背景
简化描述一下问题的背景:
有两个服务 服务A 和服务B;
- 服务B是线上业务的一个下游服务,是一个异步的编排服务,机器多且QPS比较高。
- 服务A是一个工具平台,可以模拟线上参数调用服务B的上游,但是会在 Trace中添加特殊的Debug标记,服务B及其上游识别到这个标记就会额外的吐出一些用于排查问题的Debug信息。
然后介绍一下Trace,是公司内部的一个分布式链路追踪系统;开放了一个能力:服务可以在Trace中添加自定义KV,向下游所有服务透传,服务A也就是依赖这个功能得以低耦合的实现。而Trace的底层原理:服务内使用ThreadLoacal,服务间靠公司的中间件适配来保证传递。
这里是使用最简单的方式描述了Trace的原理,实际实现起来复杂的多;因为使用了ThreadLocal来保证请求维度的信息透传,所以在遇到线程池、回调、RPC等场景都需要进行特殊处理,显然是公司的基研团队进行了大量的适配。也同样是这些不容易看到的适配导致这次排查会比较困难。
需要交代的前置条件如上,下面描述问题:
五一假期结束之后,通过打点发现服务B中大量的请求的Trace中带上了Debug标记[1],明显不符合预期且会对线上服务造成一定压力。下面分条描述现象:
- 含有Debug标记的请求占比在假期期间稳步上升,复工之后开始间歇性陡增;但是只有服务B有这个现象,上游服务没有受到影响。
- 虽然集群的Debug请求占比在5%左右,但是分机器看这个比例并不均匀;高的机器会把20%的机器当作Debug请求,而大半机器是正常的,不会在Trace中无中生有Debug标记。
- 在灰度链路压力测试时,如果时刚刚发布的机器,进行压测是正常的,所有请求都不会带Debug标记; 之后使用服务A手动发送几条带有Debug标记的请求,则后续的许多压测流量都会莫名带上Debgu标记。今天临下班的时候在一台机器上复现出了100%把请求识别为带有Debug标记的情况。
排查情况
Trace、ThreadLocal与线程池
经过几天的排查,发现自己对于这三个东西的认知还是比较浅薄、趁着下班读一读源码 Debug瞅一瞅。
线程池
主要是读了一下ThreadPoolExecutor的源码,以FAQ的形式记录一下自己阅读过程中产生的问题以及答案。
F: ThreadPoolExecutor中使用Worker来管理线程,Worker还实现了AQS用于标记线程的状态,这个操作有必要么? 为什么不通过Thread.getState()方法来判断目标线程的状态?
A:有必要。这里需要澄清一个概念,workers中线程的状态只有两种:即线程是否正在进行工作。 而Thread.getStatus()则是反应线程的真实状态。
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
@Override
protected boolean isHeldExclusively() {
return getState() != 0;
}按照提问的这个思路,如果Thread.getStatus()返回的是waiting,是否代表线程池中的当前线程是空闲的,可以随时杀掉? 错,Thread.getStatus()返回waiting只能代表当前线程正在等待,完全有可能是向线程池提交了一个IO任务,线程正在等待IO的结果。
所以,必须引入一个锁才可以准确的表明线程池中的当前线程是否正在处理submit上来的任务,从而保证可以在安全的时机对线程进行中断/释放等操作。
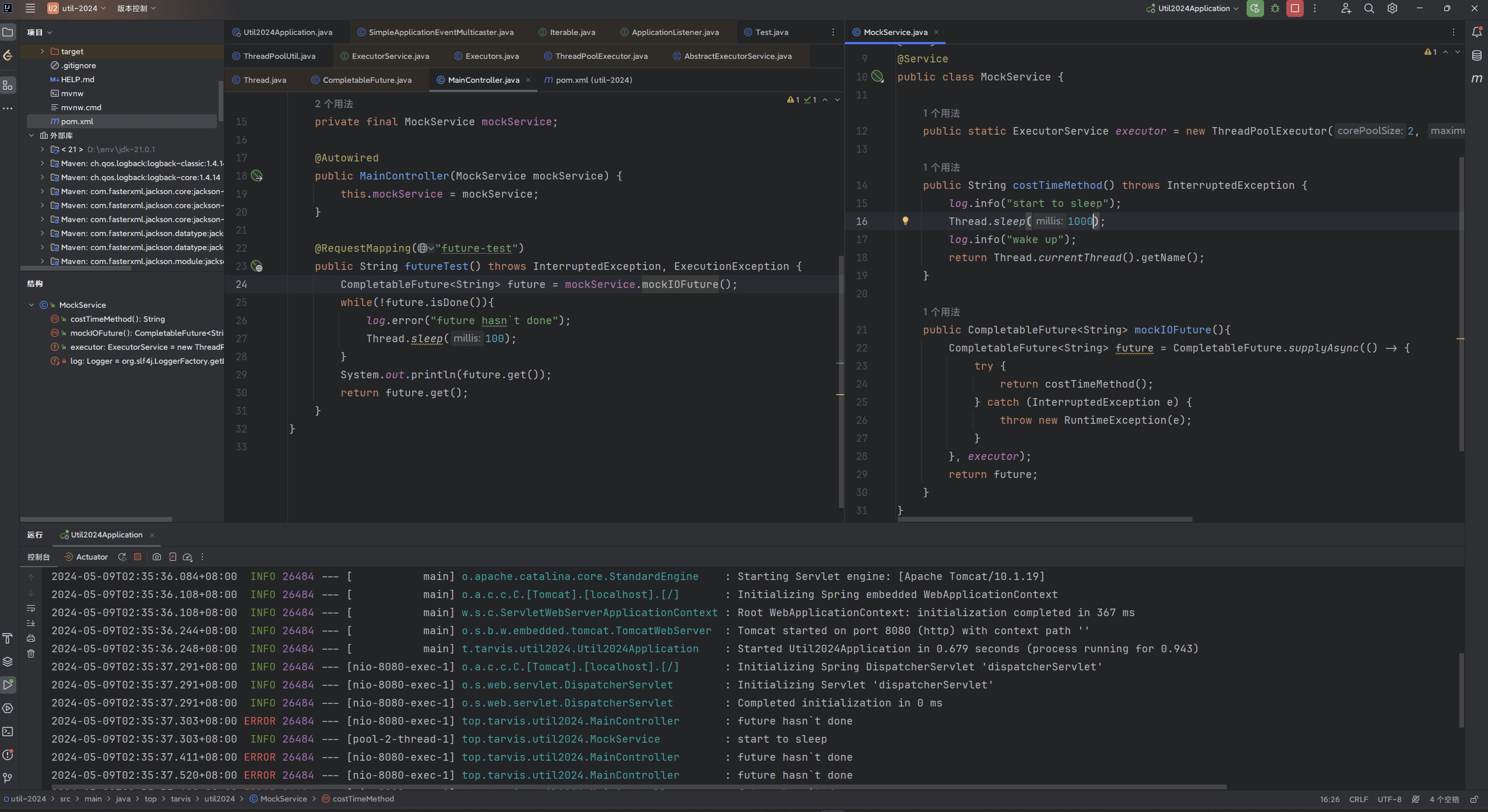
这个有助于理解Future这一概念,可以看到先打印出了一行
future hasn\t done 然后才开始start to sleep`; 可以推断出Future开始运行的时机 以及supplyAsync的返回时机。

蹲个后续