项目的灵感已经太过久远不可考了,可能是想捡起来荒废已久的python、或者是想尝试一下spring以外的框架写起来是甚么感觉、也可能是冲浪到了什么奇怪的网站想要探索更多互联网角落吧~
功能
从一个网页出发,遇到这个网页中指向其他网站的链接就点进去并将网页信息(title,description之类)存进数据库,就这样漫无目的的在互联网上乱逛
实现
这个爬虫本身仍然逃不脱所谓的爬虫循环:
- 通过给定的URL生成一个初始request,并指定一个用于处理response的回调函数
- 在回调函数中拆分response(网页)并返回[1]:
a. scrapy中定义的item我看就是一个dict
b. 一个类似步骤一中的指定回调的request;scrapy会继续发送这个request并交由回调处理 (net_elder 实现互联网上遛弯的核心,DFS遍整个互联网) - 在回调函数中使用scrapy提供的CSS选择器将目标数据提取出来并组合成item;在这个项目中只需要提取标签a相关的信息即可
- 最后通过ItemPipLine将item信息持久化进数据库即可


暂时就这些,代码已经开源在Github了 传送
完成(2.11)
赶在开学前终于是弄完了,过程还是比较坎坷的,毕竟是脱离了舒适圈的几乎全新技术栈~ 当然也有自己脑子不够清醒的原因在
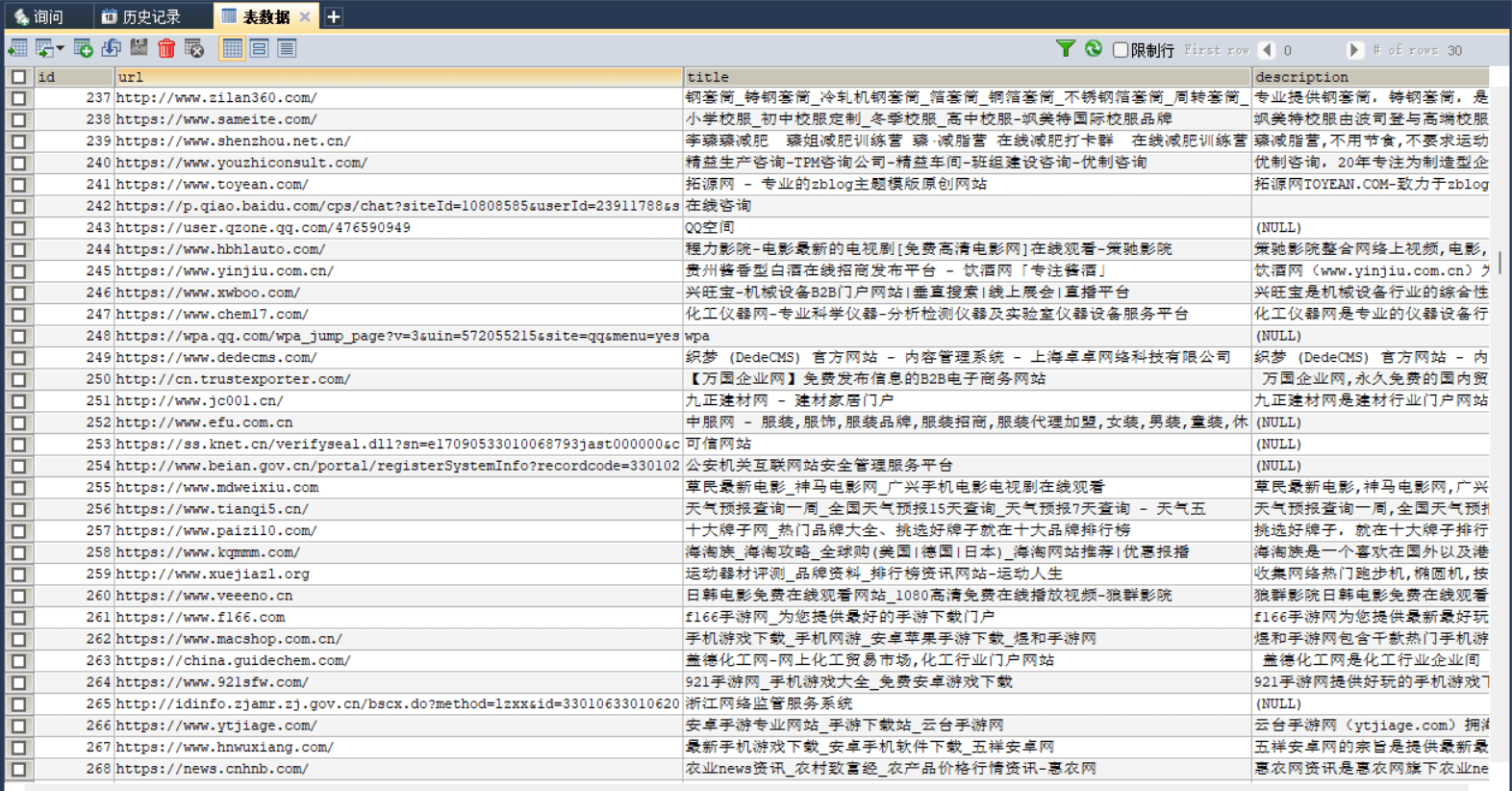
可能是由于这个爬虫逻辑过于简单了并且种子过于单调吧,并没有爬到太多有趣的网站,而且大概爬了几百个中文互联网有就跳到英文互联网再也不回来了…… 看来要加点不可描述的网站做种子才行
吐槽
为什么用 ’python+mysql' 做关键词搜出来的文章都是推荐用pandas来搞啊?我照着写写写,怎么看这个pandas都不像一个正常的ORM框架,哪有select操作还要自己去写语句的?你当你是Mybatis么
结果去人家pandas官网一看,人家网站第一行就是
pandas ——— 一个Python的数据分析库
……
后来用 ‘python+ORM’ 做关键词才发现在别的文章中用来建立链接的SQLAlchemy 本身就是一个完整的ORM框架…… 写起来顺手多了
SQLAlchemy的官方文档真的很乱,如果想快速上手ORM部分建议直接看Quick start部分
python的缩进可真是一点也不优雅…… for循环只有开始标志没有结束标志,导致我有一部分逻辑错写进循环里了都不知情,排查好久……
我了解的几个语言 java、go、kotlin都没有抛弃for循环的大括号,甚至rust也保留了这个feature;python这里很有为了简洁而简洁的嫌疑
后面如果 遇到有趣的技术问题 或者是上线之后 有一些奇妙的发现,我再来更新~